Why Are We Moral?
An LLM-based Agent Simulation Approach
to Study Moral Evolution
Abstract
The evolution of morality presents a puzzle: natural selection should favor self-interest, yet humans developed moral systems promoting altruism. Traditional approaches must abstract away cognitive processes, leaving open how cognitive factors shape moral evolution. We introduce an LLM-based agent simulation framework that brings cognitive realism to this question: agents with varying moral dispositions perceive, remember, reason, and decide in a simulated prehistoric hunter-gatherer society. This enables us to manipulate factors that traditional models cannot represent—such as moral type observability and communication bandwidth—and to discover emergent cognitive mechanisms from agent interactions. Across 20 runs spanning four settings, we find that cooperation and mutual help are the central driver of evolutionary survival, with universal and reciprocal morality exhibiting the most stable outcomes across conditions while selfishness is strongly disfavoured. Beyond cooperation itself, we further identify cognition as a central mediator—most clearly through a cost of moral judgment that shifts the winning moral type across settings, with a self-purging effect among selfish agents as an additional cognitive pattern. We validate robustness across multiple LLM backbones, architecture ablations, and prompt-sensitivity analyses. This work establishes LLM-based simulation as a powerful new paradigm to complement traditional research in evolutionary biology and anthropology.
The paradox
Survival favours the self-interested.
Every calorie, every risk, every act of help has a cost. A rational strategy should hoard, defect, and free-ride.
We feed strangers. We punish cheaters at personal cost. We mourn the unknown dead.
Moral systems promoting altruism, reciprocity, and universal concern are everywhere—across cultures, across millennia.
Why? What kind of process could produce morality out of a game that rewards selfishness?
Why cognitive realism? A new research paradigm
Prior approaches to moral evolution—evolutionary game theory, agent-based models, anthropological fieldwork—share two simplifications. Agents are reduced to fixed strategies or payoff entries, and the world is reduced to an abstract game. This prevents investigation of how cognitive factors (memory of past interactions, the ability to identify others' moral dispositions, communication bandwidth, reasoning under uncertainty) and richer environmental pressures together shape moral evolution.
LLM-based agent simulation relaxes both simplifications. Agents become cognitive—they perceive, remember, reason, and reflect under a moral value—and the world becomes a prehistoric hunter-gatherer ecology with plants, prey, social coalitions, conflict, and reproduction. Cognition and environment shift from hidden modelling assumptions to first-class experimental variables. This opens up mechanisms like self-purging and the cost of moral judgment that are inaccessible to fixed-strategy models, and action-level resolution lets us trace why a moral type fails by examining individual agents' reasoning.
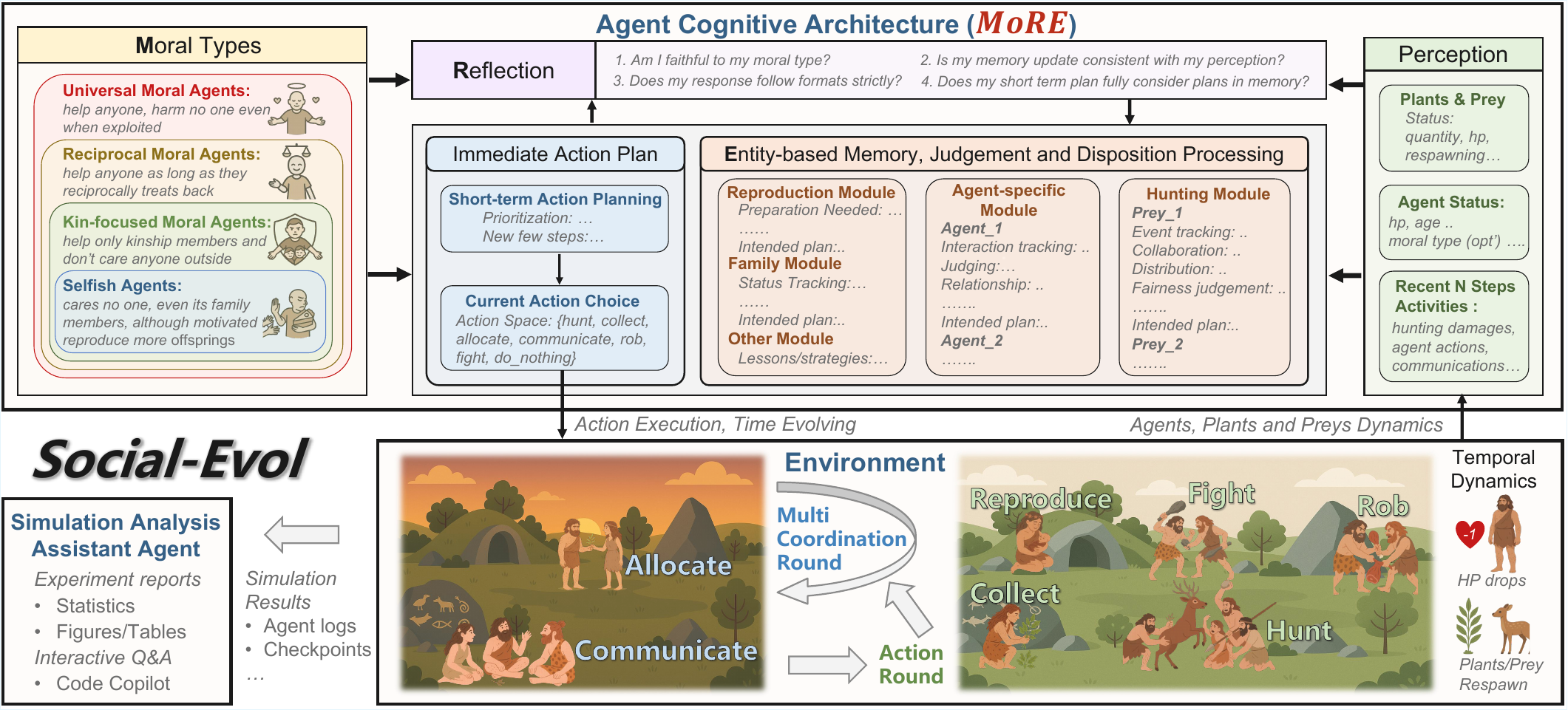
Framework
Each agent is built on MoRE—a morality-driven, entity-oriented cognitive architecture with reflection. A moral value module (one of four dispositions) conditions how the agent perceives entities, updates per-entity memory and judgments, plans actions, and reflects for consistency with observed facts before executing. Memory is organised per entity rather than as an undifferentiated event log, allowing agents to maintain and update distinct representations of each peer.
The environment, Social-Evol, simulates a prehistoric hunter-gatherer society. HP decays over time and from injury; death occurs at HP = 0 or maximum lifespan. Agents choose among eight action types each step. Crucially, there is no built-in punishment for antisocial behaviour: cooperation emerges (or fails to emerge) from the interaction of cognition, morality, and ecology alone.
The four moral dispositions
Agents differ only in the radius of their moral concern, following the philosophical tradition of the expanding circle:
Main findings
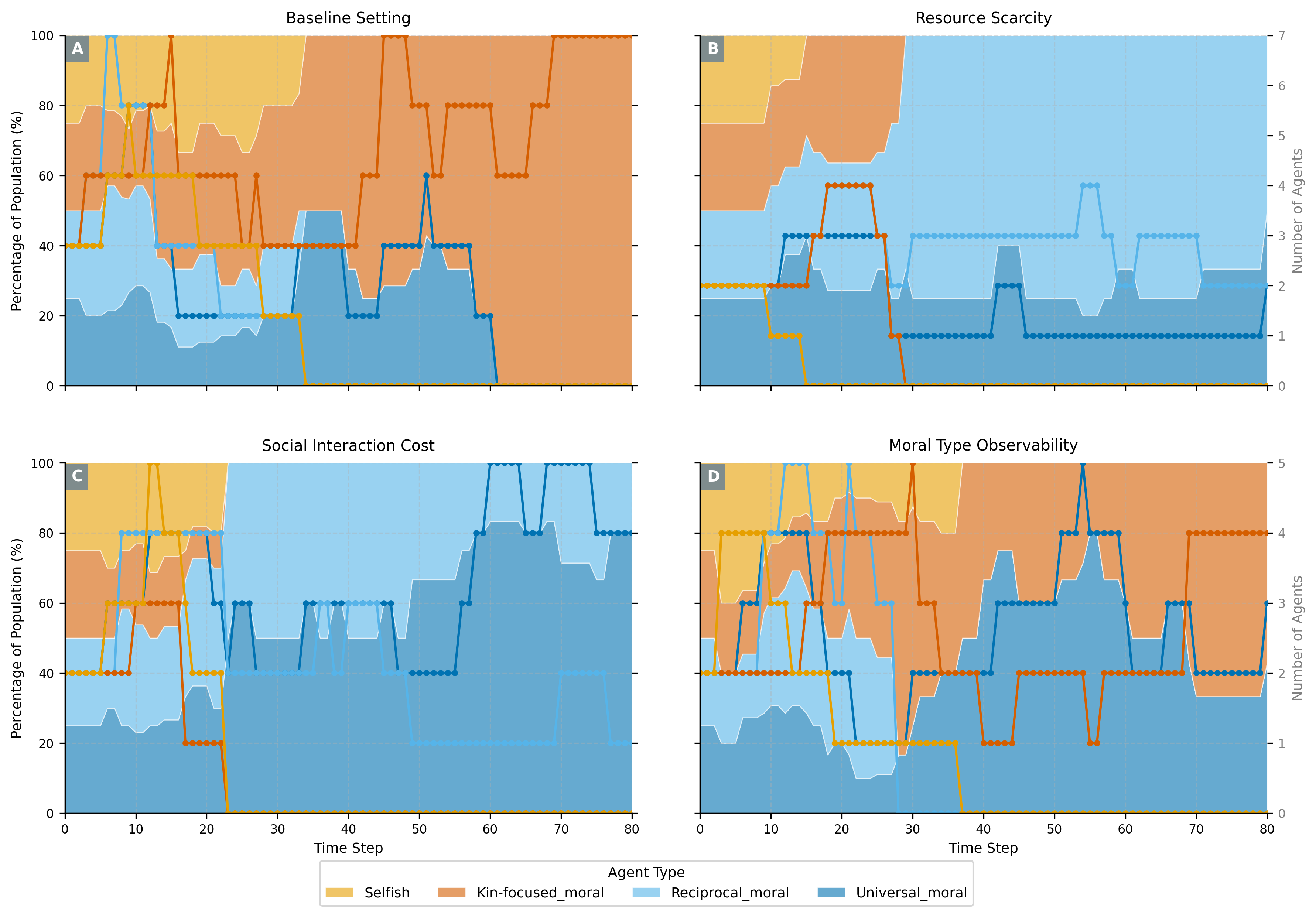
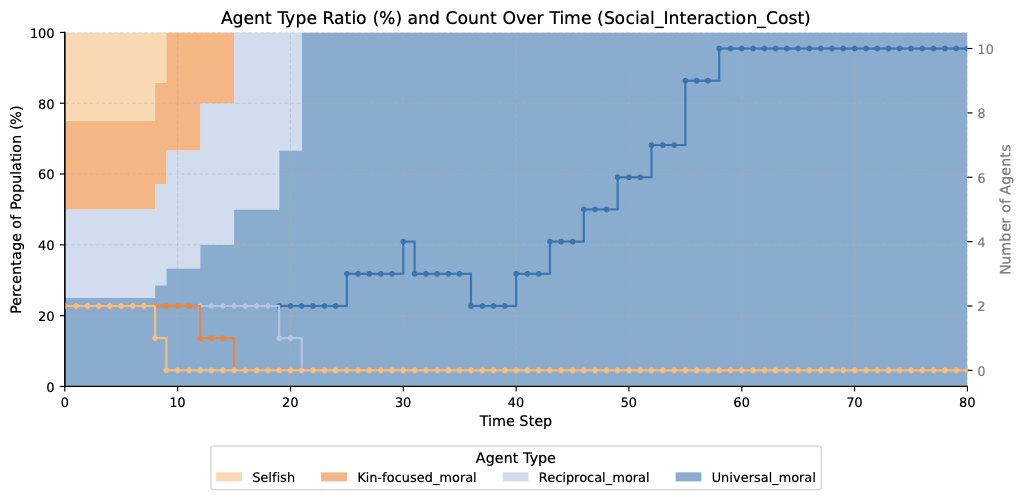
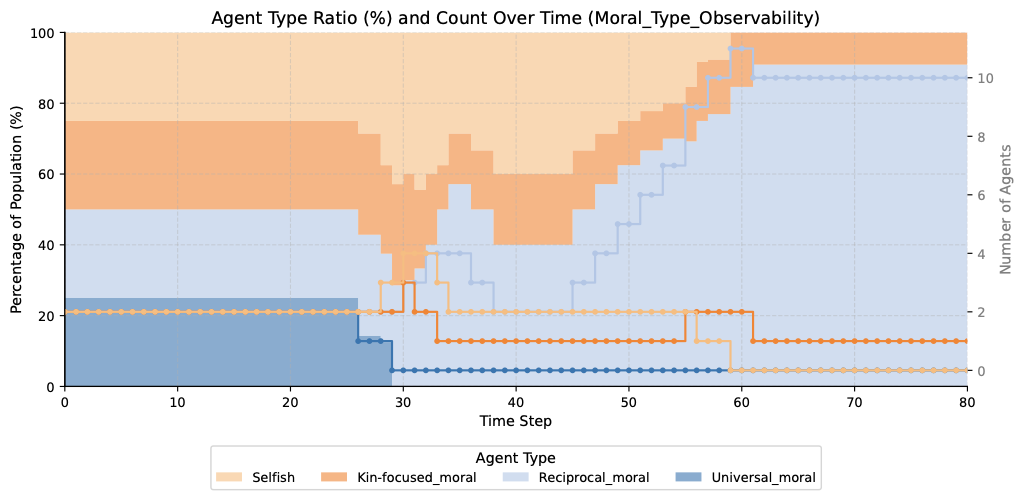
Four settings, four evolutionary outcomes
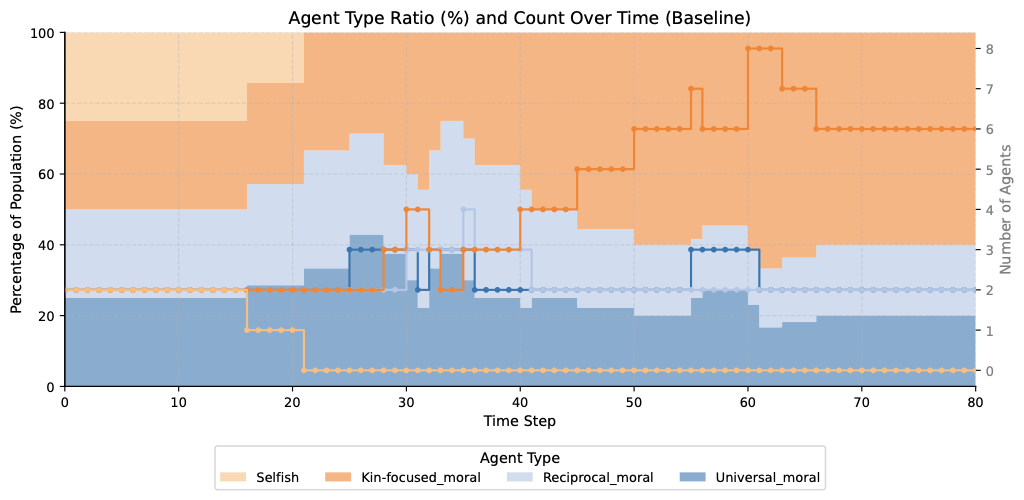
Baseline
Kin 6/8 · Universal 4/8With abundant resources, observable moral types, and sufficient social interaction rounds, kin lineages grow self-sustaining and gain a compounding advantage through internal family cooperation. Universal agents also survive frequently, indicating that broader moral circles remain competitive even under favourable conditions.
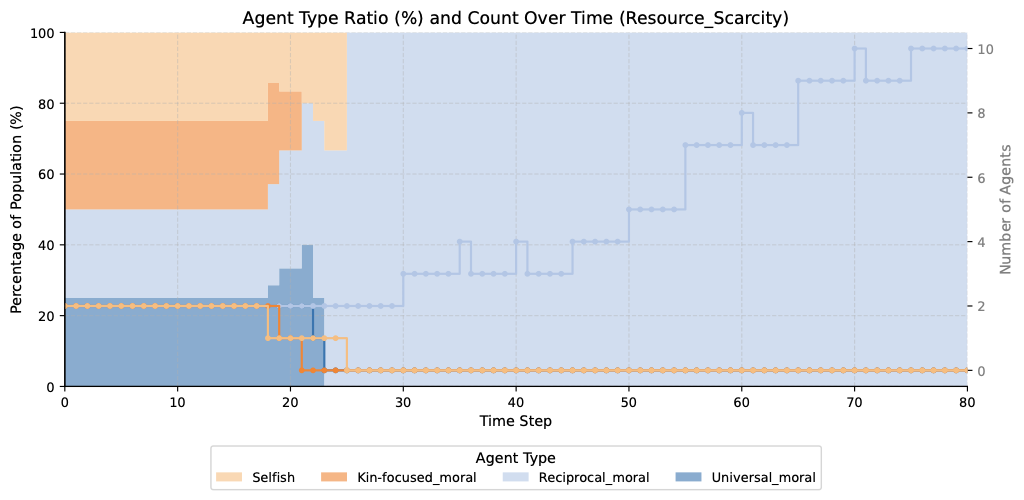
Scarce Resource
Reciprocal 3/4 · Universal 2/4Under reduced resource abundance, agents selectively avoid less cooperative partners. Reciprocal's conditional cooperation ensures fair resource sharing within coalitions while excluding free-riders. Notably, we also observe the self-purging pattern here: selfish agents preemptively attack one another, reasoning that others—especially fellow selfish agents who will neither help them nor share—pose a life-and-death competitive threat. Universal agents, by contrast, do not perceive others as such threats and avoid this kind of aggression.
High Social Cost
Reciprocal 3/4 · Universal 2/4With only one communication round before production, kin-focused agents cannot confirm the explicit teaming signals their strategy requires and drop out. Universal agents contribute unconditionally; reciprocal agents directly identify trustworthy partners without lengthy negotiation. Both form effective coalitions; selfish agents rarely persist.
Moral Type Invisible
Universal 4/4 · Reciprocal 2/4 · Kin 2/4 · Selfish 0/4When moral type labels are hidden, universal agents cooperate regardless of others' types and are never misread as uncooperative—surviving in every run. Reciprocal agents suffer from noisy type inference; kin-focused agents briefly appear cooperative until selectivity is detected. Selfish agents are quickly exposed through aggression and eliminated in every run.
What cognition adds to the story
Two cognitive patterns emerge from the simulations—neither is explicitly encoded, yet both decisively shape evolutionary outcomes and deepen our understanding of why cooperation prevails. The first is the central mediator beyond cooperation itself; the second is an additional observation that helps explain why selfishness fails so completely.
I. The cost of moral judgment
Assessing others' trustworthiness takes time under limited lifespans and carries the risk of misjudgment—wrongly excluding allies, or being wrongly excluded. Universal agents uniquely sidestep this cost: they never produce behaviours that could be misread, so their reputation settles quickly. When judgment cost is high, a “willing-to-take-a-loss” strategy therefore builds reputation faster and secures better cooperation—connecting to costly signalling and bounded rationality from neighbouring fields. This mediator explains why the winning cooperative strategy shifts across settings: reciprocal when types are visible, universal precisely when judgment becomes costly (Type Invisible, High Social Cost).
II. Self-purging of selfish agents
In the Scarce Resource setting, selfish agents preemptively attack one another, reasoning that others—especially fellow selfish agents who will neither help them nor share resources—pose a life-and-death competitive threat. Universal agents, by contrast, do not perceive others as such threats and avoid this aggression. Self-purging is thus the natural strategic outcome of cognition applied to a selfish value system: the ability to assess others' cooperative intent becomes, for selfish agents, the ability to identify rivals worth preemptively eliminating. Selfishness fails through both its lack of positive benefits and this self-destructive dynamic.
Both patterns trace directly to relaxing the two simplifications of prior work: they require agents who form beliefs about one another, can misjudge, and act on those beliefs in a richer world—capabilities that payoff-matrix games cannot express. Action-level resolution further lets us trace why a type fails by examining individual agents' reasoning.
Validation
We validate the simulation along four axes—summarised below, then detailed in the figures.
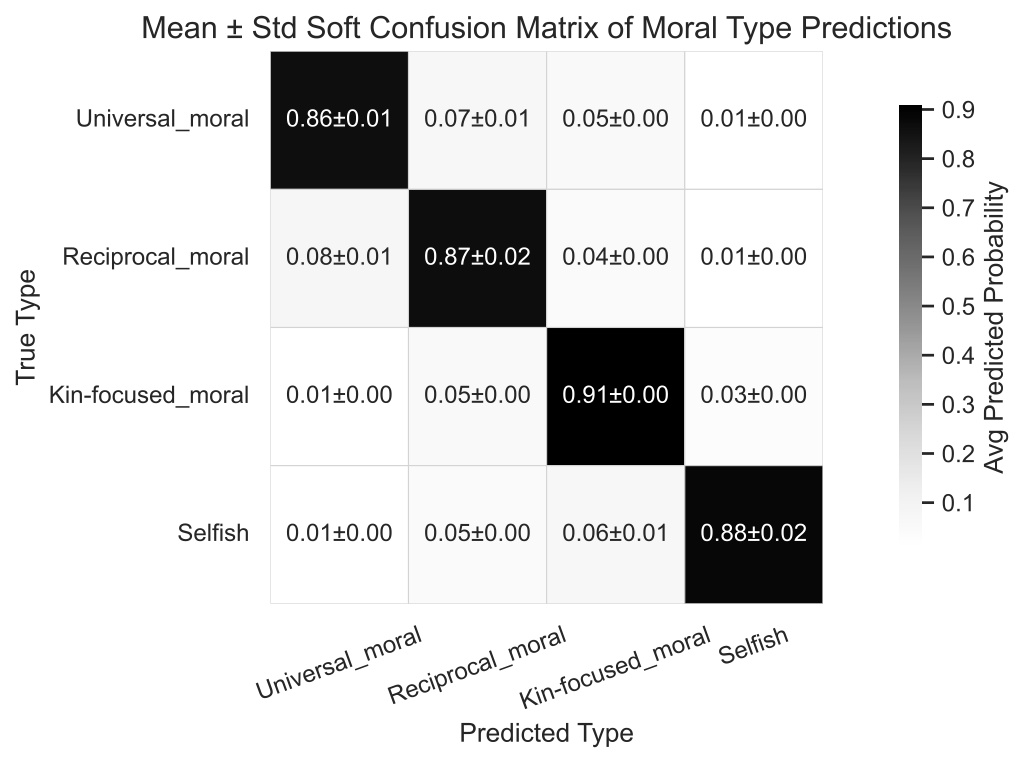
Independent GPT-5 evaluator infers each agent's moral type from observed behaviour alone (diagonal accuracy, mean over 8 runs). Moral dispositions produce recoverable behaviour.
Baseline reproduces with Qwen-3.5 and Kimi-K2.5 beyond the primary GPT-5-mini—consistent alignment across LLM families.
Removing any single cognitive module degrades alignment (largest drop: long-term memory). Stripping all modules drops accuracy to 0.67—each MoRE component contributes beyond standard LLM reasoning.
Two semantically equivalent rewrites of the moral-type prompts yield negligible variation—results do not hinge on specific wording.
A common venue for previously isolated theories
The simulations also surface—without any prior encoding—a range of effects that are well established in neighbouring fields but have rarely been brought into the study of moral evolution: coordination costs under bounded rationality (economics), impression formation from observed behaviour (social psychology), costly signalling, altruistic punishment, life-history trade-offs in reproductive timing, and the anthropological sequence of kin-focused cooperation preceding expanded moral circles under environmental pressure. They emerge bottom-up from cognitive agent interactions rather than being built in as assumptions, offering a common venue in which these previously isolated mechanisms can jointly bear on moral evolution.
Beyond morality
The framework also generalises beyond morality. By defining different prompt templates, researchers can study cultural backgrounds, religions, political views, or custom social norms within the same hunter-gatherer engine. We hope this paradigm inspires broader and deeper investigations into moral and social evolution.
Citation
@inproceedings{zhou2026moral,
title = {Why Are We Moral? An {LLM}-based Agent Simulation Approach
to Study Moral Evolution},
author = {Zhou, Ziheng and Tang, Huacong and Bi, Mingjie and Kang, Yipeng
and He, Wanying and Sun, Fang and Sun, Yizhou and Wu, Ying Nian
and Terzopoulos, Demetri and Zhong, Fangwei},
booktitle = {Proceedings of the Annual Meeting of the Association
for Computational Linguistics (ACL)},
year = {2026}
}